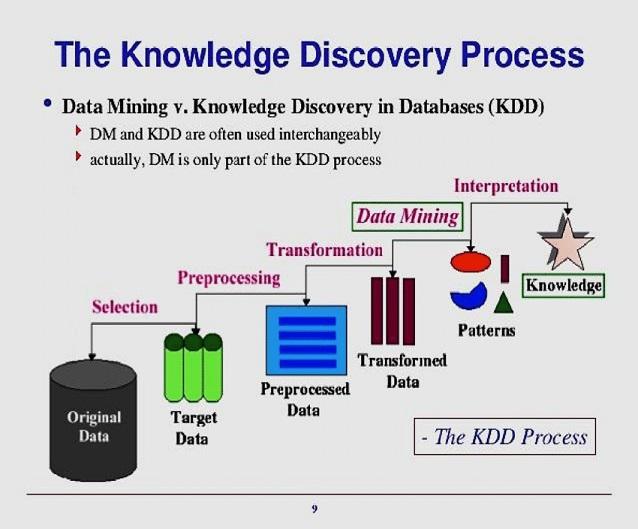
Data mining (DM) applies machine learning techniques and statistical models to uncover hidden patterns in large data sets (Big Data analytics) especially in the context of KDD (knowledge discovery in databases). Data mining is the analysis step of the KDD process.
- Data mining approaches
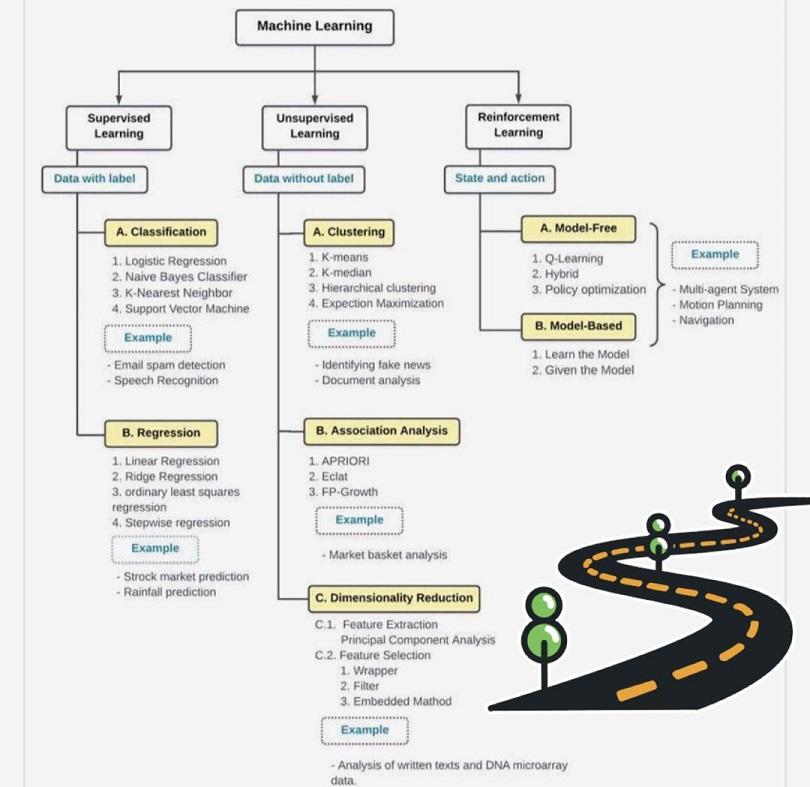
- Supervised ML techniques
- Unsupervised ML techniques
You may also be interested in Normal distribution or Gaussian distribution.
DM software: IBM SPSS modular, SASS, SAS, SPSS, weka (open source)
Data mining approaches
DM involves the systematic analysis of data using automated methods to identify patterns such as groups of data records (cluster analysis), unusual records (anomaly detection), and relationships (association rule mining, sequential pattern mining). DM can be understood as a process of applying machine learning (ML) methods – such as neural networks, cluster analysis, decision trees, and support vector machines – to uncover hidden patterns in large data sets. The identified patterns can be used in further analysis, for example, in predictive analytics.
While the KDD process is commonly defined with the five stages of selection, preprocessing, transformation, data mining, and interpretation, the leading industry KDD methodology is CRISP-DM (cross-industry standard process for data mining), followed by SEMMA (Sample, Explore, Modify, Model, and Assess). CRISP-DM defines six high-level phases: business understanding, data understanding, data preparation, modeling, evaluation, and deployment.
Before data mining algorithms can be used, a target data set is assembled. A common source for data is a data mart or data warehouse. The target data must be of manageable size, large enough to contain patterns and concise enough to be mined within an acceptable time limit. The target data set is then cleaned to remove duplicate or irrelevant observations and/or to handle missing data. The data is then processed (transformed) to an analysis-ready format.
1. Supervised ML techniques
In supervised ML, labeled data sets are used to train or “supervise” algorithms. The models are trained by being shown a known set of inputs (features) and corresponding outputs (labels) from which they learn the prediction task of inferring the output values.
1.1. Classification techniques:
Classification techniques are used to predict a discrete number of values (labels) according to some parameters. They include decision tree, logistic regression, neural networks (NN), Naive Bayes Classifier, K-Nearest Neighbors (memory-based reasoning), and support vector machine.
Business technology applications: signature-based IDS, email spam detection, speech recognition, facial recognition, the likelihood to churn, and the likelihood to purchase.
1.2. Regression techniques:
Regression techniques are used to predict continuous values. They include linear regression, ridge regression, ordinary least squares regression, and stepwise regression.
Business technology applications: stock market prediction, sales forecast prediction, rain fall prediction, financial portfolio prediction, salary forecasting, and quantifying the advertising-revenue association.

2. Unsupervised ML techniques
In unsupervised ML, algorithms are used to discover and identify hidden patterns in data without the need for human intervention. Models have a known set of inputs (features) and no corresponding outputs (labels).
2.1. Clustering:
Clustering techniques are used to partition data sets into groups (clusters) without labels associated with them. Clustering techniques include k-means clustering, nearest neighbor, and agglomerative and hierarchical clustering techniques.
Business technology applications: anomaly-based IDS, identification of fake news, document analysis, segmentation of consumer base in the market, and analysis of social networks.
2.2. Association:
Business technology applications: market basket analysis.
Related content
A framework for understanding NLP
Decision tree for classification problems
Google Data Analytics Professional Certificate quiz answers
Google IT Support Professional Certificate quiz answers
How to break into information security
IT career paths – everything you need to know
Predictive analytics application areas and process
The Security Operations Center (SOC) career path
What is the Google Data Analytics certification?
Back to DTI Courses
Other content
1st Annual University of Ottawa Supervisor Bullying ESG Business Risk Assessment Briefing
Disgraced uOttawa President Jacques Frémont ignores bullying problem
How to end supervisor bullying at uOttawa
PhD in DTI uOttawa program review
Rocci Luppicini – Supervisor bullying at uOttawa case updates
The case for policy reform: Tyranny
The trouble with uOttawa Prof. A. Vellino
The ugly truth about uOttawa Prof. Liam Peyton
uOttawa engineering supervisor bullying scandal
uOttawa President Jacques Frémont ignores university bullying problem
uOttawa Prof. Liam Peyton denies academic support to postdoc
Updated uOttawa policies and regulations: A power grab
What you must know about uOttawa Prof. Rocci Luppicini
Why a PhD from uOttawa may not be worth the paper it’s printed on
Why uOttawa Prof. Andre Vellino refused academic support to postdoc