This lesson covers two important L4 protocols, TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) – how they function and their characteristics. TCP and UDP are mentioned in Section 1.0 Network Fundamentals, subsection 1.5, of the CCNA exam topics list, which says you must be able to “Compare TCP to UDP”.
First, the basic functions of TCP and UDP are discussed, focusing on how they provide 1) transparent transfer of data between end hosts, 2) various services to applications, and 3) Layer 4 addressing to deliver data to the correct destination. We discuss how L4 ports are used to identify application services and to track sessions between end hosts and servers (session multiplexing). IANA’s port number ranges that Application layer protocols use are then explained.
We then zoom in on TCP. First we explain why TCP is a connection-oriented protocol. So we look at the three-way handshake and the four-way handshake. We then discuss TCP functions in closer detail, especially, how TCP provides sequencing, reliable communication, and flow control. We then move on to UDP, highlighting how it is similar to and different from TCP. We compare TCP to UDP. We compare the fields in the L4 headers of each of the two transport protocols, the features, and the real-world applications of each protocol. Last but not least, we look at important well-known port numbers and matching Application layer protocols we must know for the CCNA. This post constitutes Issue 24 of my CCNA 200-301 study notes.
- Basic functions of Layer 4 protocols (Transport layer)
- Port numbers/session multiplexing
- IANA’s port number ranges
- TCP (Transmission Control Protocol)
- TCP header
- Establishing connections: three-way handshake
- Terminating connections: four-way handshake
- Sequencing/Acknowledgement
- TCP retransmission
- Error recovery
- TCP flow control: window size
- Why TCP is stateful
- UDP (User Datagram Protocol)
- Comparing TCP to UDP
- Port numbers
- Key learnings
- Key references
You may also be interested in How to get started with Wireshark.
Basic functions of Layer 4 protocols (Transport layer)
Layer 4 protocols have three basic functions: 1) provide transparent transfer of data between end hosts, 2) provide (or not provide) various services to applications, and 3) provide Layer 4 addressing (port numbers) to deliver data to the correct destination.
Let’s elaborate.
The first function of Layer 4 protocols is to provide transparent transfer of data between end hosts. This means that the applications running on the end hosts do not need to be aware of the details of the network or the Transport layer protocol. The applications simply send data to the Transport layer, and the Transport layer ensures that it is delivered to the correct destination.
In this network topology Host A is sending data to Host B.
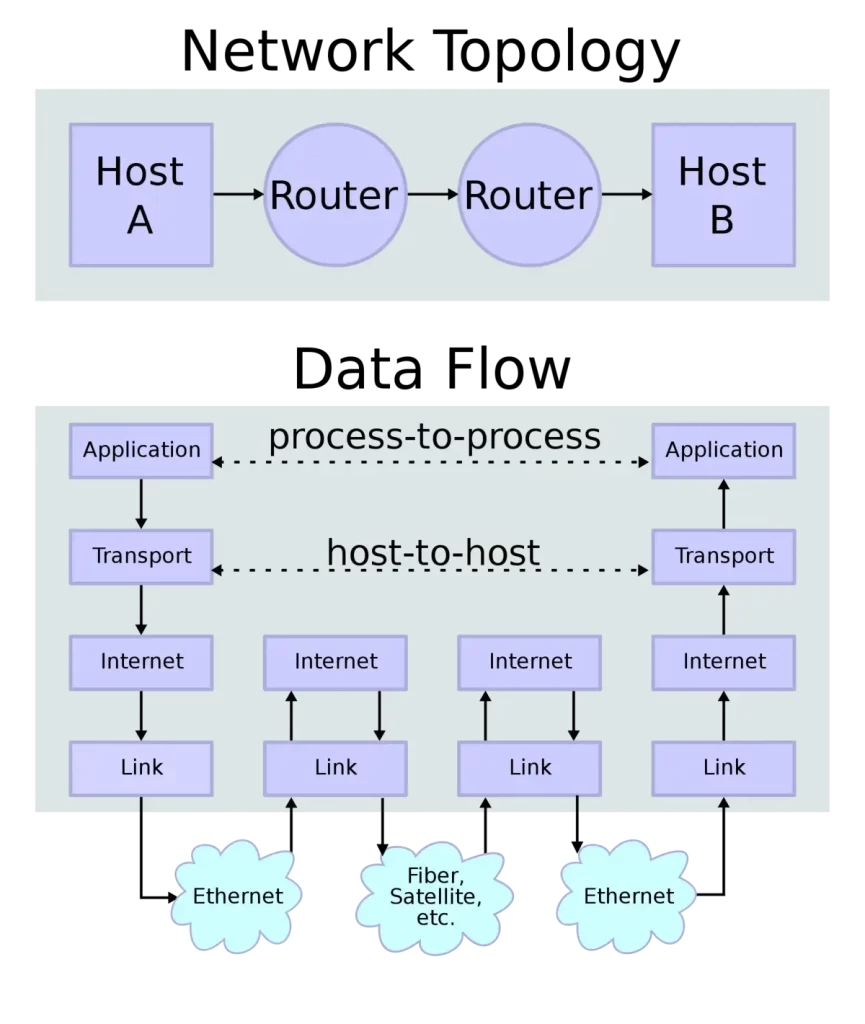
The Transport layer encapsulates the data with a Layer 4 header, and then uses the services of the lower layers, Layers 3, 2, and 1, to deliver the data unchanged to the destination host. The hosts themselves are not aware of the details of the underlying network, the transfer of data is transparent to them.
A second function of Layer 4 protocols is to provide, or not provide, various services to applications. TCP provides services to applications whereas UDP does not.
The following are services provided by TCP but not UDP.
- Reliable data transfer. That means making sure that the destination host actually received every bit of data that it’s supposed to.
- Error recovery. If an error occurs in transmission, Layer 4 can ensure the data is sent again.
- Data sequencing, making sure that even if data arrives at the destination out of order, the end host can sequence it in the correct order.
- Flow control, making sure that the source host does not send traffic faster than the destination host can handle.
TCP provides data transfer reliability at L4 by making use of three fields (Sequence Number, Acknowledge Number, and Window Size) and four flags (SYN/Synchronize, ACK/Acknowledgement, FIN/Finished, and RST/Reset) in the TCP header. More on this shortly.
A third function of Layer 4 protocols is to provide Layer 4 addressing. Layer 4 addressing is a way of identifying a network host at the Transport layer. Layer 4 addressing is used by transport protocols TCP and UDP to deliver data to the correct destination.
Layer 4 addressing consists of two parts: a transport protocol identifier and a port number. The transport protocol identifier is a 2-bit number that identifies the transport protocol that is being used. The port number is a 16-bit number that identifies the specific application or process on the destination host that is receiving the data.
For example, the following is a Layer 4 address for a TCP connection to the HTTP port on a web server:
TCP:80
The TCP part of the address identifies the transport protocol, and the 80 part of the address identifies the port number for HTTP, which is a protocol used to access webpages.
TCP:80 is the well-known port number for the HTTP protocol. This means that any TCP packet that is addressed to TCP:80 will be routed to the HTTP server on the destination host.
Layer 4 addressing is used by transport protocols to ensure that data is delivered to the correct destination. It is also used by firewalls and routers to control the flow of traffic on a network.
L4 ports provide two key functions:
- Identifying the Application layer protocol that is being used (e.g., HTTP).
- Providing session multiplexing.
L4 ports are used to identify the Application layer protocol and service because they are used to tell the Transport layer which application to send the data to. The Transport layer is responsible for delivering data to the appropriate application process on the host computers. This involves statistical multiplexing of data from different application processes, i.e. forming data segments, and adding source and destination port numbers in the header of each Transport layer data segment. The source IP address, the destination IP address, and the port number together constitute a network socket, i.e. an identification address of the process-to-process communication.
Here are some examples of L4 ports and the Application layer protocols and services they identify:
- Port 80: HTTP (Hypertext Transfer Protocol) is the protocol used to transfer hypertext documents, such as HTML, between web browsers and web servers.
- Port 443: HTTPS (Hypertext Transfer Protocol Secure) is a secure version of HTTP that uses encryption to protect the data that is transferred between the web browser and the web server.
- Port 21: FTP (File Transfer Protocol) is the protocol used to transfer files between two computers.
- Port 25: SMTP (Simple Mail Transfer Protocol) is the protocol used to send email messages.
- Port 110: POP3 (Post Office Protocol version 3) is a protocol used to receive email messages from a mail server.
- Port 143: IMAP4 (Internet Message Access Protocol version 4) is a protocol used to receive email messages from a mail server.
Port numbers/session multiplexing
Here we have PC1, and it will access resources from two servers over the Internet, SRV1 and SRV2.
Let’s see how L4 ports can be used to identify the application service PC1 wants to access, and to track sessions between PC1 and the servers.
A session is an exchange of data between two or more communicating devices. A PC is typically handling multiple communication sessions at once. A PC user typically has several web browser tabs open at any one time, accessing different services over the Internet. The user probably has multiple services running on his computer that need Internet access.
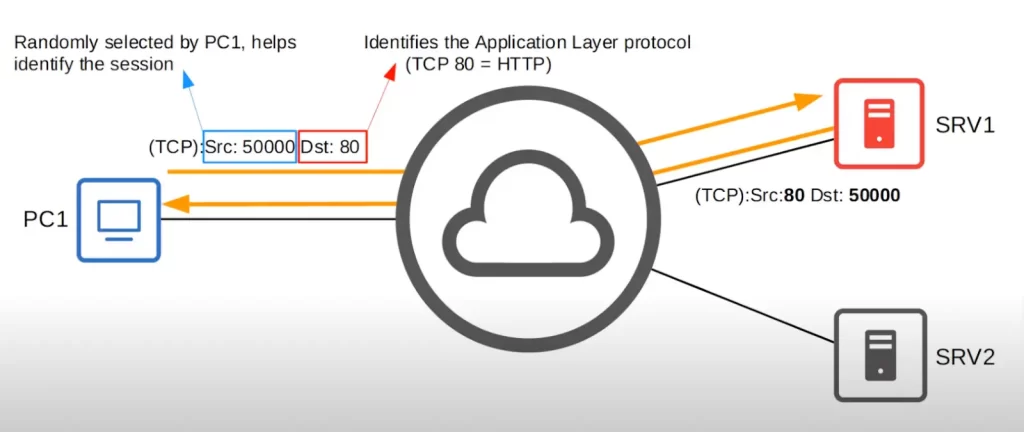
When PC1 sends a TCP packet to the server SRV1, the TCP packet will include the source port 50000 and the destination port 80 in the packet header. SRV1 will then respond to the packet with a TCP packet of its own, which will also include the source port 80 and the destination port 50000.
The source port is randomly selected by PC1. The destination port identifies the Application layer protocol. For example, TCP port 80 is used for HTTP, which is used to access websites. Perhaps SRV1 is hosting a webpage that PC1 wants to access.
The combination of source port and destination port help identify the session. For example, after SRV1 receives PC1’s message it will probably send a reply. In SRV1’s reply, the source and destination port numbers are reversed, the source port is 80 and the destination is 50000. When PC1 receives this message, PC1 will know from the source and destination port numbers that the message is part of the same communication session as the message it sent earlier.
PC1 may open a separate connection to SRV1 using HTTP at destination port 80 again, but using a different source port. SRV1 will respond by using that source port as the destination port for its response so PC1 knows the response message is part of that session. PC1 may want to access another service on SRV2 at the same time. So it uses a TCP destination port number of 21, and randomly selects the source port 60000. TCP port 21 is used for FTP (File Transfer Protocol), which is used to transfer files.
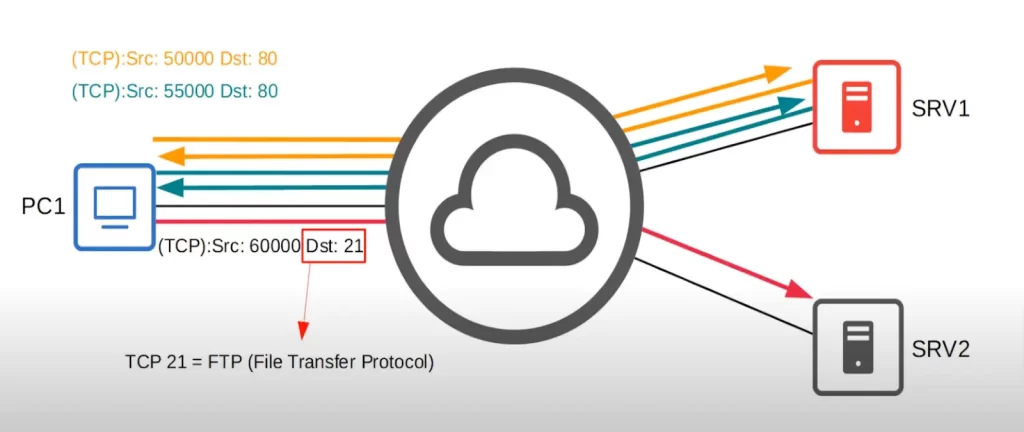
SRV2 will reply using a source port of 21 and destination port of 60000. These will tell PC1 that this communication is part of the same session.
The use of different source and destination ports in a TCP connection allows multiple applications on the same computer to communicate with each other over the same network. For example, PC1 could be using a web browser to connect to a web server, while also using a file transfer protocol (FTP) client to connect to an FTP server. In this case, the web browser would use the source port 50000, while the FTP client would use a different source port.
That was a basic explanation of how ports identify the Application layer protocol, such as HTTP or FTP. We also saw how port numbers can be used by hosts to manage multiple communication sessions at once.
IANA’s port number ranges
The port numbers that Application layer protocols use are registered with the IANA, the Internet Assigned Numbers Authority. IANA has designated the following port number ranges.
- Well-known port numbers are ports 0 through 1023. These are used for major protocols like HTTP, FTP, etc, and are very strictly regulated.
- Registered port numbers are in the range 1024 to 49151. Registration is required to use these port numbers, although it’s not as strict as with the well-known port range.
- The range 49152 through 65535 is used for ephemeral ports, also known as private or dynamic ports. Hosts use this range when selecting the random source port.
As you probably noticed, all of the randomly selected source port numbers in the previous example came from the ephemeral port range.
TCP (Transmission Control Protocol)
After an overview of the functions of the TCP, we will look at the TCP header, and then go more in depth on a few of its functions.
*TCP is a connection-oriented protocol.
>The source host does not start sending data without first communicating with the destination host and setting up a connection. Once a connection is established, the data exchange begins.
*TCP provides reliable communication.
>The destination host must acknowledge that it received each TCP segment.
>If the source host does not receive an acknowledgment for a segment, the source host sends the segment again.
*TCP provides sequencing.
>There is a sequence field in the TCP header.
>Destination hosts use the sequence numbers in the TCP header to put segments in the correct order even if they arrive out of order.
*TCP provides flow control.
>The destination host can tell the source host to increase or decrease the rate of data transfer (flow), so that the destination host is not overwhelmed by traffic.
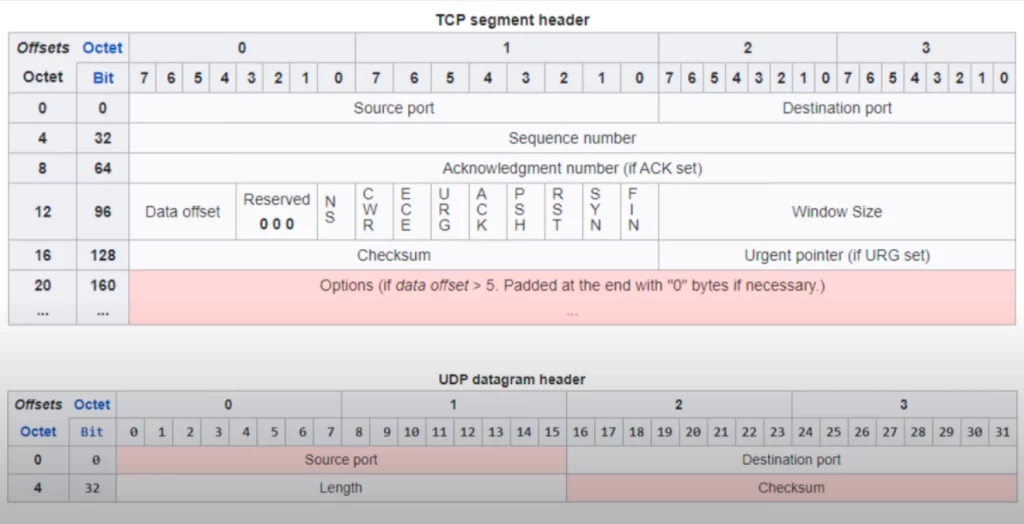
TCP header
As you can see in the TCP header diagram below, there are a few fields and flags in the TCP header that are used to provide those different services we mentioned.
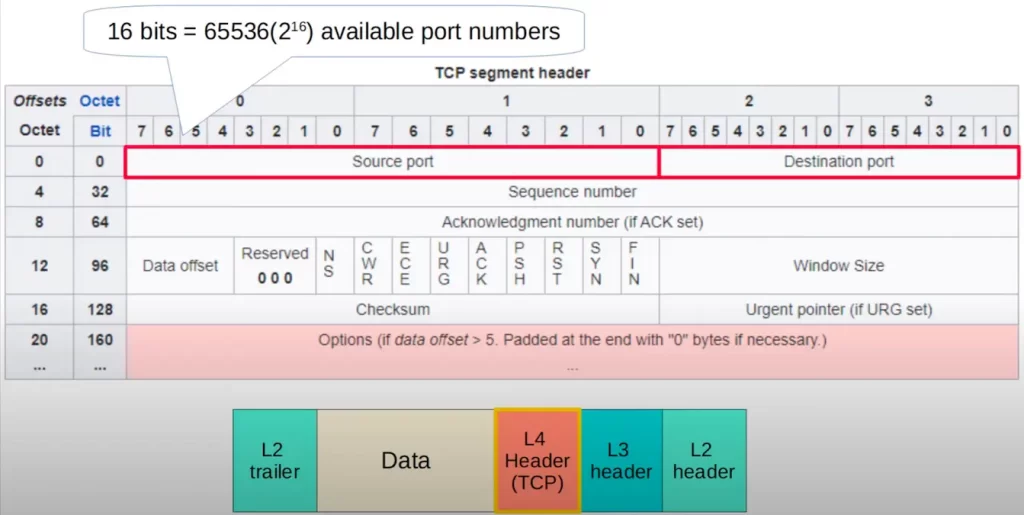
Note that each of the source and destination port fields is 16 bits (2 bytes) in length. So there are a total of 65536 available port numbers (2 to the power of 16).
The next two fields are the sequence number and acknowledgment number. These two fields are used to provide sequencing and reliable communication.
TCP has a series of flag bits that have different functions. ACK, SYN, and FIN are used to establish and terminate connections.
The window size field is used for flow control, adjusting the rate at which data is sent.
Establishing connections: three-way handshake
TCP is connection-oriented, meaning, hosts first communicate to establish a connection before sending any data. The method TCP uses to establish connections is called the TCP Three-Way Handshake. The method involves three messages being sent between any two hosts.
Let’s say PC1 wants to access a webpage on SRV1 using HTTP. First, PC1 must establish a TCP connection. To do so, PC1 uses two flags in the TCP header, SYN (synchronization), and ACK (acknowledgment).

First, PC1 will send a TCP segment to SRV1 with the SYN flag set, meaning that bit is set to 1.
Secondly, SRV1 will reply by sending a TCP segment to PC1 with the SYN and ACK flags set. So both bits are set to 1.
Thirdly, PC1 will send a TCP segment with the ACK bit set.
Now the three-way handshake is complete and the connection is established. The first three messages of the three-way handshake establish a connection. Then real data exchange can begin.
Terminating connections: four-way handshake
The process TCP uses to terminate connections is sometimes called the TCP four-way handshake. When PC1 decides that it no longer needs the connection with SRV1 it will initiate this process to terminate the connection. TCP uses two flags (in the TCP header) in this process, FIN and ACK.
First, PC1 sends a TCP segment to SRV1 with the FIN flag set. SRV1 responds with an ACK.

SRV1 then sends its own FIN. Finally, PC1 sends an ACK in response to SRV1’s FIN, and the connection is terminated.
Sequencing/Acknowledgement
Let’s see how TCP uses the sequence and acknowledgment fields of the header to provide reliable communication and sequencing.
Here is an exchange between two PCs, PC1 and PC2. When PC1 sends the three-way handshake’s SYN message, PC1 sets a random initial sequence number, let’s say 10. When PC2 sends the SYN-ACK to PC1, PC2 sets its own random initial sequence number, for example 50. PC2 also acknowledges that it received PC1’s segment with the sequence number of 10, by setting the acknowledgment field to 11.
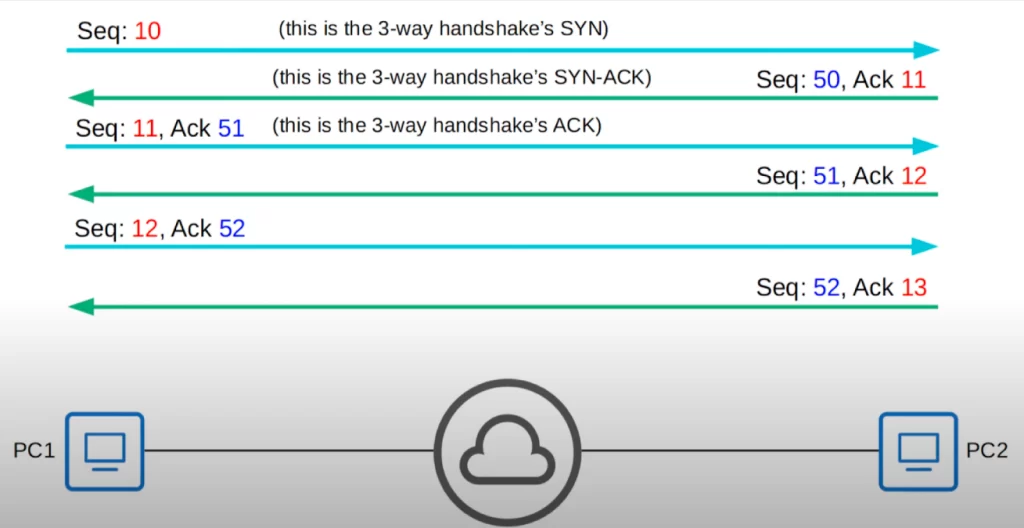
Why 11? Because TCP uses “forward acknowledgment”. Instead of acknowledging sequence number 10 with an Ack field of 10, PC2 tells PC1 the sequence number of the next segment it expects to receive.
PC1 sends the final ACK of the three-way handshake. The sequence number is 11 and the forward acknowledgment value is 51 (to acknowledge receipt of PC2’s segment with the sequence number 50). PC2 replies. The sequence number is 51, and the forward acknowledgment is set to a value of 12 in the acknowledgment field. Then the exchange continues, as shown.
Remember,
*hosts set a random initial sequence number, and
*forward acknowledgment is used to indicate the sequence number of the next segment the host expects to receive.
We saw how the sequence and acknowledgment fields of the TCP header are used to acknowledge that the host has received each TCP segment it should receive. These sequence numbers also allow hosts to know the correct order of segments, even if for some reason they arrive out of order.
TCP retransmission
To provide reliable communication, TCP retransmits any segments that are not acknowledged.
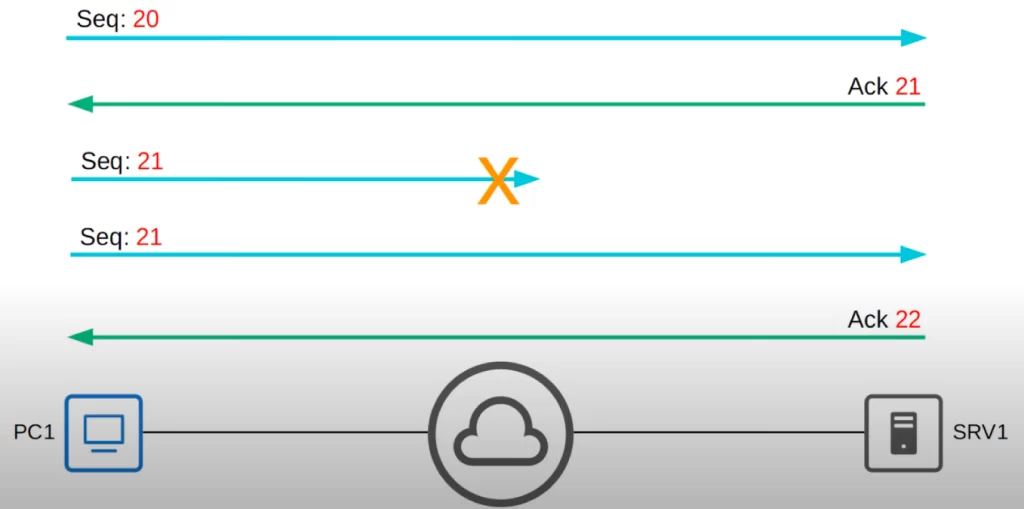
TCP retransmission works like this:
>PC1 sends SRV1 a segment with sequence number 20.
>SRV1 sends Ack 21 to PC1.
>PC1 then sends sequence number 21. But something is amiss. PC1 does not receive an Ack for sequence 21 from SRV1.
>After waiting a certain amount of time with no Ack, PC1 resends the segment.
This time SRV1 receives it, and sends Ack 22 to tell PC1 that it was received.
Error recovery
TCP provides error recovery by using a mechanism called Positive Acknowledgement with Retransmission (PAR). PAR works as follows:
- The sender sends a segment of data to the receiver.
- The receiver acknowledges (ACKs) the segment when it receives it correctly.
- If the sender does not receive an ACK within a certain timeout period, it retransmits the segment.
TCP uses a checksum to detect corrupted packets. If the receiver receives a packet with a checksum error, it discards the packet and does not send an ACK. The sender will eventually retransmit the packet, since it does not receive an ACK.
TCP also uses sequence numbers to ensure that segments are delivered in order. The sequence number is a unique identifier for each segment. When the receiver receives a segment, it checks the sequence number to make sure that the segment is in the correct order. If the receiver receives a segment with an out-of-order sequence number, it discards the segment and does not send an ACK. The sender will eventually retransmit the segment, since it does not receive an ACK.
PAR is a very effective way to recover from packet loss and corruption. It is one of the reasons why TCP is so reliable.
Here is an example of how PAR works:
- The sender sends segment 1 to the receiver.
- The receiver receives segment 1 correctly and sends an ACK 1 to the sender.
- The sender sends segment 2 to the receiver.
- Segment 2 is lost in transit.
- The sender does not receive an ACK 2 within a certain timeout period, so it retransmits segment 2.
- The receiver receives segment 2 correctly and sends an ACK 2 to the sender.
- The sender continues sending segments 3, 4, and so on.
The receiver will discard any out-of-order segments that it receives. It will also discard any duplicate segments that it receives.
TCP error recovery is an important part of what makes TCP so reliable. It allows TCP to deliver data over unreliable networks, such as the Internet.
TCP flow control: window size
Let’s discuss how TCP provides flow control.
Acknowledging every single segment, no matter what size, is inefficient. The TCP header’s window size field allows more data to be sent before an acknowledgment is required.
Here’s an example. A host could send three segments, with sequence numbers 20, 21, and 22, and then an Ack is sent with sequence number 23.
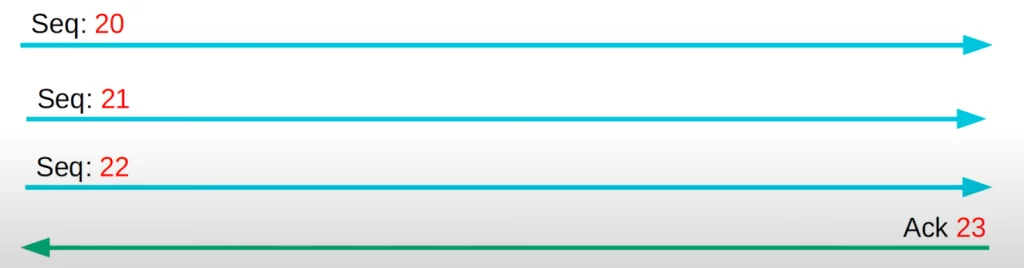
In addition, a sliding window is used to dynamically adjust the window size. The window size is increased as much as possible until a segment is dropped, then the window size shrinks back to a more reasonable size, and slowly increases again.
The previous examples used very simple sequence numbers. In real situations, the sequence numbers get much larger and do not increase by 1 with each message.
Why TCP is stateful
TCP is a stateful protocol. A stateful protocol is a communication protocol that maintains information about the state of a communication session between two or more communication peers. This information is used to ensure reliable and efficient communication.
TCP is a stateful protocol because it maintains information about the state of a TCP connection, including:
- The sequence number of the next byte of data to be sent
- The sequence number of the last byte of data that has been acknowledged by the receiver
- The window size, which is the maximum amount of data that the sender can send without waiting for an acknowledgment from the receiver
- The congestion window, which is the maximum amount of data that the sender can send without causing congestion on the network
TCP uses this information to ensure that data is delivered reliably and efficiently. For example, if a packet is lost during transmission, TCP will retransmit the packet. TCP also uses the congestion window to avoid overloading the network and causing congestion.
UDP (User Datagram Protocol)
UDP is much simpler and easier to understand than TCP.
Here is the UDP header. Four fields. That’s it. Source and destination port numbers, a length field indicating the length of the segment, and a checksum so the receiving host can check for errors.

*UDP is not connection-oriented. It is connectionless.
>Unlike TCP, in UDP the sending host does not first establish a connection with the destination host and then starts sending data. The data is simply sent.
*UDP does not provide reliable communication.
>In UDP, no acknowledgements are sent for received segments. If a segment is lost, it is not retransmitted. Segments are sent best-effort, meaning, UDP provides no guarantee of delivery like TCP. It sends segments, it makes the effort, but it does not provide any guarantees.
*UDP does not provide sequencing.
>Unlike TCP, UDP has no sequence field in its header. If segments arrive out of order, UDP has no mechanism to put them back in order.
*UDP does not provide flow control.
>UDP has no mechanism like TCP’s window size to control the flow of data.
*UDP is a stateless protocol. This means that it does not maintain any information about the state of a communication session between two or more communication peers. Each UDP packet is treated independently, and there is no concept of a TCP connection.
UDP is often used for applications where speed and low latency are more important than reliability. For example, UDP is used for streaming video and audio, as well as for online games.
Here are some of the benefits of using a stateless protocol like UDP:
- Speed: UDP is faster than TCP because it does not have to maintain any state information.
- Low latency: UDP has lower latency than TCP because it does not have to wait for acknowledgments from the receiver.
- Simplicity: UDP is simpler to implement than TCP because it does not have to maintain any state information.
Here are some of the drawbacks of using a stateless protocol like UDP:
- Unreliability: UDP does not guarantee that all data will be delivered to the receiver in the correct order, or that it will be delivered at all.
- No flow control: UDP does not have any flow control mechanisms, so it is possible for the sender to overwhelm the receiver with data.
- Limited features: UDP does not support some of the features of TCP, such as retransmission and congestion control.
Comparing TCP to UDP
First up, here are the two headers for comparison. All of the additional fields that TCP has allow it to provide additional functions like sequencing and error recovery.
In which cases would TCP be used, and in which cases would UDP be used?
*TCP provides more features than UDP, but at the cost of additional overhead because of the larger header. The additional overhead in TCP refers to the extra bytes that are added to each packet when using TCP compared to UDP. This overhead is due to the fact that TCP provides more features than UDP, such as reliable delivery, flow control, and error correction.
The TCP header is 20 bytes long, while the UDP header is only 8 bytes long. This means that each TCP packet is 12 bytes larger than a UDP packet. For small amounts of data, this overhead can be significant. However, for large amounts of data, the overhead is relatively small.
In addition, acknowledgments and retransmissions can slow down the transfer of data.
*For applications that require reliable communications, such as downloading a file, TCP is preferred. You would not want to download a PDF file with some content missing.
*UDP is preferred for applications involving real-time voice and video, for example voice over IP phone calls, Zoom, and Skype. The overhead of TCP can slow such applications.
*There are some applications that use UDP, but can provide reliability within the application itself, for example, TFTP, the Trivial File Transfer Protocol.
*Finally, some applications use both TCP & UDP, depending on the situation. DNS is an example.
Here’s a chart summarizing the key differences between TCP and UDP.
| TCP (Transmission Control Protocol) | UDP (User Datagram Protocol) |
| Connection-oriented | Connectionless |
| Reliable | Unreliable |
| Sequencing | No sequencing |
| Flow control | No flow control |
| Use for downloads, file sharing, etc. | Use for VoIP, live video, etc. |
Port numbers
Both TCP and UDP provide Layer 4 addressing in the form of port numbers. These port numbers identify Application layer protocols and allow for session multiplexing.
Here are some important well-known port numbers and matching Application layer protocols you should know for the CCNA exam.

TCP & UDP ports to know for the CCNA (summary): TCP & UDP ports for the CCNA
Two types of questions related to port numbers and TCP & UDP that come up in the CCNA exam:
- match Application layer protocols or services to port numbers
- match routed protocol (UDP or TCP) to a service or Application protocol
Some protocols that use TCP
FTP, the File Transfer Protocol, uses TCP ports 20 and 21.
SSH, Secure Shell, which is commonly used to connect to the CLI of routers and switches, uses TCP port 22.
Telnet, which can also be used to connect to the CLI of devices, uses TCP port 23.
SMTP, the Simple Mail Transfer Protocol, is used for sending email and uses TCP port 25.
HTTP, Hypertext Transfer Protocol, commonly used for accessing web pages, uses TCP port 80.
POP3, Post Office Protocol 3, used for retrieving emails, uses TCP port 110.
HTTPS, Hypertext Transfer Protocol Secure, uses TCP port 443.
Some protocols that use UDP
DHCP, Dynamic Host Configuration Protocol, which allows hosts to automatically set their IP address and other things, uses UDP ports 67 and 68.
TFTP, the Trivial File Transfer Protocol, uses UDP port 69.
SNMP, the Simple Network Management Protocol, uses UDP ports 161 and 162.
Syslog uses UDP port 514.
The only protocol you should be aware of that uses both TCP and UDP is DNS, Domain Name System. It usually uses UDP, but uses TCP in some situations.
Key learnings
*Basics of Layer 4, including Layer 4 addressing in the form of port numbers and matching transport protocol identifiers.
*TCP, a Layer 4 protocol which provides various services to applications, such as reliable communication and flow control.
*UDP, which does not provide the various services that TCP does, but uses a smaller header with less overhead.
*Comparing TCP to UDP.
Key references
Note: The resources cited below (in the “Key references” section of this document) are the main source of knowledge for these study notes/this lesson, unless stated otherwise.
Free CCNA | TCP & UDP | Day 30 | CCNA 200-301 Complete Course
Other references/resources
TCP – 12 simple ideas to explain the Transmission Control Protocol
TCP vs UDP – Explaining Facts and Debunking Myths – TCP Masterclass
TLS Handshake – EVERYTHING that happens when you visit an HTTPS website
Related content
Compliance frameworks and industry standards
Getting started with Wireshark
How data flow through the Internet
How to break into information security
IT career paths – everything you need to know
Job roles in IT and cybersecurity
Network security risk mitigation best practices
The GRC approach to managing cybersecurity
The penetration testing process
The Security Operations Center (SOC) career path
Back to DTI Courses